ETCD 备份还原¶
使用 ETCD 备份功能创建备份策略,可以将指定集群的 etcd 数据定时备份到 S3 存储中。本文主要介绍如何将已经备份的数据还原到当前集群中。
Note
下面通过具体的案例来说明备份还原的整个过程。
环境信息¶
首先介绍还原的目标集群和 S3 存储的基本信息。这里以 MinIo 作为 S3 存储,整个集群有 3 个控制面(3 个 etcd 副本)。
| IP | 主机 | 角色 | 备注 |
|---|---|---|---|
| 10.6.212.10 | host01 | k8s-master01 | k8s 节点 1 |
| 10.6.212.11 | host02 | k8s-master02 | k8s 节点 2 |
| 10.6.212.12 | host03 | k8s-master03 | k8s 节点 3 |
| 10.6.212.13 | host04 | minio | minio 服务 |
前提条件¶
安装 etcdbrctl 工具¶
为了实现 ETCD 数据备份还原,需要在上述任意一个 Kubernetes 节点上安装 etcdbrctl 开源工具。 此工具暂时没有二进制文件,需要自行编译。编译方式请参考 Gardener / etcd-backup-restore 本地开发文档。
安装完成后用如下命令检查工具是否可用:
预期输出如下:
INFO[0000] etcd-backup-restore Version: v0.23.0-dev
INFO[0000] Git SHA: b980beec
INFO[0000] Go Version: go1.19.3
INFO[0000] Go OS/Arch: linux/amd64
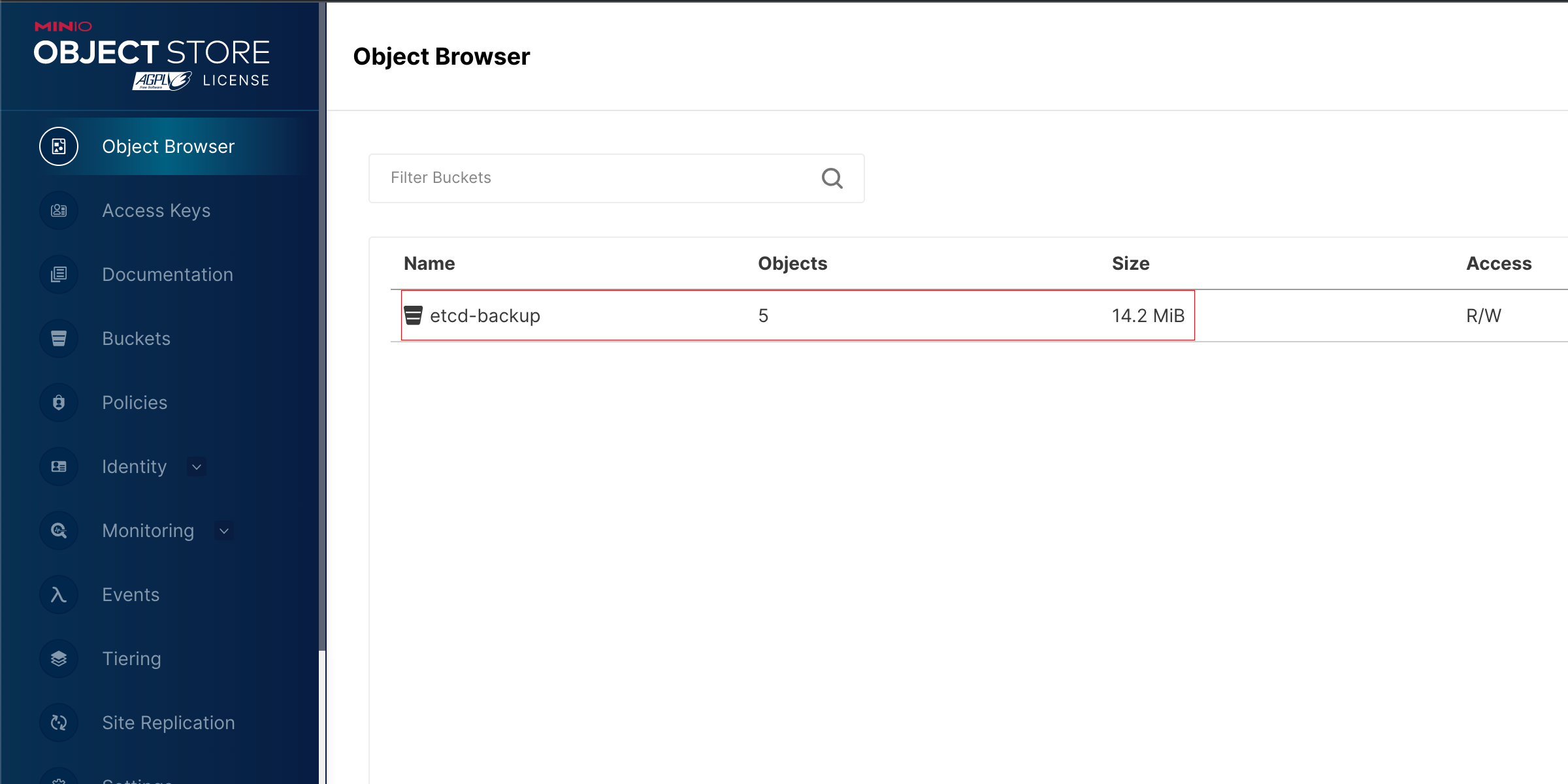
检查备份数据¶
还原之前需要检查下列事项:
- 是否已经在 DCE 5.0 中成功备份了数据
- 检查 S3 存储中备份数据是否存在
Note
DCE 5.0 的备份是全量数据备份,还原时将还原最后一次备份的全量数据。
关闭集群¶
在备份之前,必须要先关闭集群。默认集群 etcd 和 kube-apiserver 都是以静态 Pod 的形式启动的。 这里的关闭集群是指将静态 Pod manifest 文件移动到 /etc/kubernetes/manifest 目录外,集群就会移除对应 Pod,达到关闭服务的作用。
-
首先删除之前的备份数据,移除数据并非将现有 etcd 数据删除,而是指修改 etcd 数据目录的名称。 等备份还原成功之后再删除此目录。这样做的目的是,如果 etcd 备份还原失败,还可以尝试还原当前集群。此步骤每个节点均需执行。
-
然后需要关闭 kube-apiserver 的服务,确保 etcd 的数据没有新变化。此步骤每个节点均需执行。
-
同时还需要关闭 etcd 的服务。此步骤每个节点均需执行。
-
确保所有控制平面的 kube-apiserver 和 etcd 服务都已经关闭。
-
关闭所有的节点后,使用如下命令检查 etcd 集群状态。此命令在任意一个节点执行即可。
endpoints 的值需要替换为实际节点名称
etcdctl endpoint status --endpoints=controller-node-1:2379,controller-node-2:2379,controller-node-3:2379 -w table \ --cacert="/etc/kubernetes/ssl/etcd/ca.crt" \ --cert="/etc/kubernetes/ssl/apiserver-etcd-client.crt" \ --key="/etc/kubernetes/ssl/apiserver-etcd-client.key"预期输出如下,表示所有的 etcd 节点都被销毁:
{"level":"warn","ts":"2023-03-29T17:51:50.817+0800","logger":"etcd-client","caller":"v3@v3.5.6/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc0001ba000/controller-node-1:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = latest balancer error: last connection error: connection error: desc = \"transport: Error while dialing dial tcp 10.5.14.31:2379: connect: connection refused\""} Failed to get the status of endpoint controller-node-1:2379 (context deadline exceeded) {"level":"warn","ts":"2023-03-29T17:51:55.818+0800","logger":"etcd-client","caller":"v3@v3.5.6/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc0001ba000/controller-node-2:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = latest balancer error: last connection error: connection error: desc = \"transport: Error while dialing dial tcp 10.5.14.32:2379: connect: connection refused\""} Failed to get the status of endpoint controller-node-2:2379 (context deadline exceeded) {"level":"warn","ts":"2023-03-29T17:52:00.820+0800","logger":"etcd-client","caller":"v3@v3.5.6/retry_interceptor.go:62","msg":"retrying of unary invoker failed","target":"etcd-endpoints://0xc0001ba000/controller-node-1:2379","attempt":0,"error":"rpc error: code = DeadlineExceeded desc = latest balancer error: last connection error: connection error: desc = \"transport: Error while dialing dial tcp 10.5.14.33:2379: connect: connection refused\""} Failed to get the status of endpoint controller-node-3:2379 (context deadline exceeded) +----------+----+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +----------+----+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ +----------+----+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
还原备份¶
只需要还原一个节点的数据,其他节点的 etcd 数据就会自动进行同步。
-
设置环境变量
使用 etcdbrctl 还原数据之前,执行如下命令将连接 S3 的认证信息设置为环境变量:
export ECS_ENDPOINT=http://10.6.212.13:9000 # (1)! export ECS_ACCESS_KEY_ID=AKIAIOSFODNN7EXAMPLE # (2)! export ECS_SECRET_ACCESS_KEY=wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY # (3)!- S3 存储的访问点
- S3 存储的用户名
- S3 存储的密码
-
执行还原操作
执行 etcdbrctl 命令行工具执行还原,这是最关键的一步。
etcdbrctl restore --data-dir /var/lib/etcd/ --store-container="etcd-backup" \ --storage-provider=ECS \ --initial-cluster=controller-node1=https://10.6.212.10:2380 \ --initial-advertise-peer-urls=https://10.6.212.10:2380参数说明如下:
- --data-dir: etcd 数据目录,此目录必须跟 etcd 数据目录一致,etcd 才能正常加载数据。
- --store-container:S3 存储的位置,MinIO 中对应的 bucket,必须跟数据备份的 bucket 相对应。
- --initial-cluster:etcd 初始化配置, etcd 集群的名称必须跟原来一致。
- --initial-advertise-peer-urls:etcd member 集群之间访问地址。必须跟 etcd 的配置保持一致。
预期输出如下:
INFO[0000] Finding latest set of snapshot to recover from... INFO[0000] Restoring from base snapshot: Full-00000000-00111147-1679991074 actor=restorer INFO[0001] successfully fetched data of base snapshot in 1.241380207 seconds actor=restorer {"level":"info","ts":1680011221.2511616,"caller":"mvcc/kvstore.go:380","msg":"restored last compact revision","meta-bucket-name":"meta","meta-bucket-name-key":"finishedCompactRev","restored-compact-revision":110327} {"level":"info","ts":1680011221.3045986,"caller":"membership/cluster.go:392","msg":"added member","cluster-id":"66638454b9dd7b8a","local-member-id":"0","added-peer-id":"123c2503a378fc46","added-peer-peer-urls":["https://10.6.212.10:2380"]} INFO[0001] Starting embedded etcd server... actor=restorer .... {"level":"info","ts":"2023-03-28T13:47:02.922Z","caller":"embed/etcd.go:565","msg":"stopped serving peer traffic","address":"127.0.0.1:37161"} {"level":"info","ts":"2023-03-28T13:47:02.922Z","caller":"embed/etcd.go:367","msg":"closed etcd server","name":"default","data-dir":"/var/lib/etcd","advertise-peer-urls":["http://localhost:0"],"advertise-client-urls":["http://localhost:0"]} INFO[0003] Successfully restored the etcd data directory. -
以下命令在节点 01 上执行,为了恢复节点 01 的 etcd 服务。
首先将 etcd 静态 Pod 的 manifest 文件移动到 /etc/kubernetes/manifests 目录下,kubelet 将会重启 etcd:
然后等待 etcd 服务启动完成以后,检查 etcd 的状态,etcd 相关证书默认目录: /etc/kubernetes/ssl 。如果集群证书存放在其他位置,请指定对应路径。
-
检查 etcd 集群列表:
etcdctl member list -w table \ --cacert="/etc/kubernetes/ssl/etcd/ca.crt" \ --cert="/etc/kubernetes/ssl/apiserver-etcd-client.crt" \ --key="/etc/kubernetes/ssl/apiserver-etcd-client.key"预期输出如下:
+------------------+---------+-------------------+--------------------------+--------------------------+------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+-------------------+--------------------------+--------------------------+------------+ | 123c2503a378fc46 | started | controller-node-1 | https://10.6.212.10:2380 | https://10.6.212.10:2379 | false | +------------------+---------+-------------------+--------------------------+--------------------------+------------+ -
查看 controller-node-1 状态:
etcdctl endpoint status --endpoints=controller-node-1:2379 -w table \ --cacert="/etc/kubernetes/ssl/etcd/ca.crt" \ --cert="/etc/kubernetes/ssl/apiserver-etcd-client.crt" \ --key="/etc/kubernetes/ssl/apiserver-etcd-client.key"预期输出如下:
+------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | controller-node-1:2379 | 123c2503a378fc46 | 3.5.6 | 15 MB | true | false | 3 | 1200 | 1199 | | +------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
-
-
恢复其他节点数据
上述步骤已经还原了节点 01 的数据,若想要还原其他节点数据,只需要将 etcd 的 Pod 启动起来,让 etcd 自己完成数据同步。
-
在节点 02 和节点 03 都执行相同的操作:
-
etcd member 集群之间的数据同步需要一定的时间,可以查看 etcd 集群状态,确保所有 etcd 集群正常:
检查 etcd 集群状态是否正常:
etcdctl member list -w table \ --cacert="/etc/kubernetes/ssl/etcd/ca.crt" \ --cert="/etc/kubernetes/ssl/apiserver-etcd-client.crt" \ --key="/etc/kubernetes/ssl/apiserver-etcd-client.key"预期输出如下:
+------------------+---------+-------------------+-------------------------+-------------------------+------------+ | ID | STATUS | NAME | PEER ADDRS | CLIENT ADDRS | IS LEARNER | +------------------+---------+-------------------+-------------------------+-------------------------+------------+ | 6ea47110c5a87c03 | started | controller-node-1 | https://10.5.14.31:2380 | https://10.5.14.31:2379 | false | | e222e199f1e318c4 | started | controller-node-2 | https://10.5.14.32:2380 | https://10.5.14.32:2379 | false | | f64eeda321aabe2d | started | controller-node-3 | https://10.5.14.33:2380 | https://10.5.14.33:2379 | false | +------------------+---------+-------------------+-------------------------+-------------------------+------------+检查 3 个 member 节点是否正常:
etcdctl endpoint status --endpoints=controller-node-1:2379,controller-node-2:2379,controller-node-3:2379 -w table \ --cacert="/etc/kubernetes/ssl/etcd/ca.crt" \ --cert="/etc/kubernetes/ssl/apiserver-etcd-client.crt" \ --key="/etc/kubernetes/ssl/apiserver-etcd-client.key"预期输出如下:
+------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | controller-node-1:2379 | 6ea47110c5a87c03 | 3.5.6 | 88 MB | true | false | 6 | 199008 | 199008 | | | controller-node-2:2379 | e222e199f1e318c4 | 3.5.6 | 88 MB | false | false | 6 | 199114 | 199114 | | | controller-node-3:2379 | f64eeda321aabe2d | 3.5.6 | 88 MB | false | false | 6 | 199316 | 199316 | | +------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
-
恢复集群¶
等所有节点的 etcd 数据同步完成后,则可以将 kube-apiserver 进行重新启动,将整个集群恢复到可访问状态:
-
重新启动 node1 的 kube-apiserver 服务
-
重新启动 node2 的 kube-apiserver 服务
-
重新启动 node3 的 kube-apiserver 服务
-
等待 kubelet 将 kube-apiserver 启动后,检查还原的 k8s 数据是否正常:
预期输出如下: